
Universally Unique Identifiers (UUIDs) have been the backbone of distributed systems for decades. When building a monolithic application, auto-incrementing integers (like
1, 2, 3...UUIDs solve this by providing 128-bit numbers that are practically guaranteed to be universally unique across the entire spacetime continuum.
For the last 20 years, UUID v4 has been the undisputed industry standard. However, the recent introduction of UUID v7 (officially standardized in RFC 9562) has fundamentally disrupted how backend engineers architect their relational databases. Let’s explore the deep mathematical differences and why you might need to migrate.
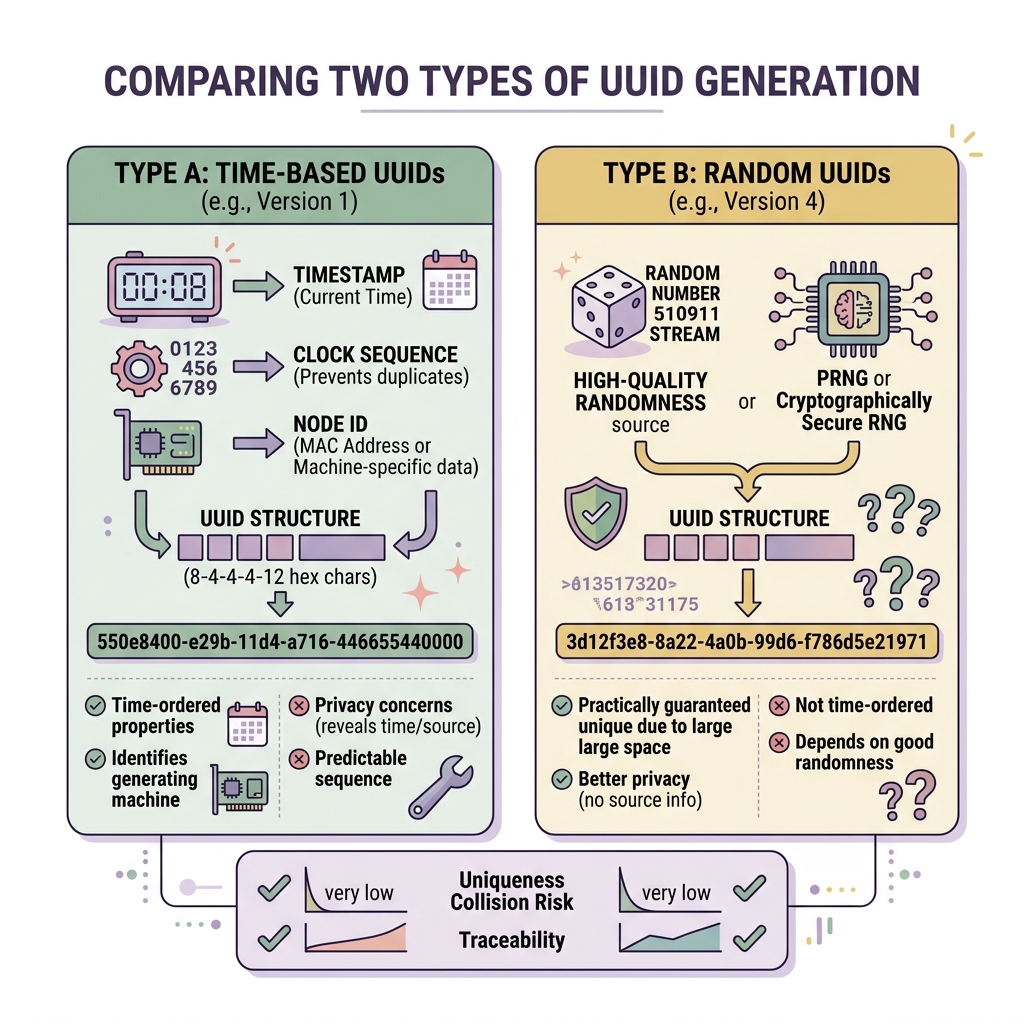
UUID v4: Pure Mathematical Randomness
A UUID v4 is built using purely random mathematical entropy generated by your operating system’s cryptographic random number generator (CSPRNG).
How it Works
A standard UUID contains exactly 128 bits. In Version 4, 122 of those bits are completely, pseudo-randomly generated. (The remaining 6 bits are strictly reserved for declaring the specific version and variant).
Example UUID v4: 9b1deb4d-3b7d-4bad-9bdd-2b0d7b3dcb6dtext
The Advantages
- Absolute Unpredictability: Because every single character is fundamentally random, malicious actors absolutely cannot guess a user's ID. This makes v4 perfect for resetting passwords, email verification links, or API secret keys.
- Infinite Offline Generation: A mobile client can generate ten thousand UUID v4 records while physically completely disconnected from the internet, and securely sync them to the master backend later knowing absolutely zero collisions will occur.
The Catastrophic Flaw: Database Fragmentation
If you use UUID v4 as the Primary Key in a traditional relational database (like PostgreSQL, MySQL, or SQL Server), you will inevitably destroy your indexing performance at scale.
Relational databases store records physically on disk using B-Tree Indexes. B-Trees are actively optimized to store sequential data (like
1, 2, 3A, B, CINSERTAt 100 million rows, this phenomenon—known as "Index Fragmentation" or "Page Splitting"—will utterly decimate your disk I/O performance and cripple your server's RAM as the database desperately struggles to keep the fragmented index cached.
UUID v7: The Time-Ordered Savior
The IETF formally ratified UUID v7 exactly to solve the massive B-Tree fragmentation crisis caused historically by v4.
How it Works
UUID v7 intelligently splits the 128-bit structure into two completely distinct physical halves:
- The Timestamp (48 bits): The absolute first 48 physical bits natively contain the exact current Unix Epoch millisecond timestamp.
- The Entropy (74 bits): The remaining operational bits precisely contain the same mathematically unpredictable cryptographic randomness utilized natively by v4.
Example UUID v7: 018e9c4b-1492-74d3-aae2-132d78b8fbf4text
The Massive Database Advantages
Because you are essentially stamping the exact chronological microsecond directly onto the very front of the UUID natively, new UUID v7s are fundamentally inherently sequential.
If you generate a thousand UUID v7s in a row, they will structurally sort themselves perfectly in chronological order natively. When you explicitly
INSERTYou receive all the decentralized parallel-generation benefits natively of UUID v4, specifically gracefully merged locally alongside the elite operational
INSERTWhich Should You Use Architecturally?
Use UUID v7 When:
- Architecting the Primary Key (PK) definitively for literally any new modern Relational Database table (Postgres, MySQL, SQLite).
- Designing massive time-series event architectures or scalable logging pipelines naturally demanding chronological traversal natively.
- Generating explicit cursor-pagination tracking variables seamlessly for frontend API responses.
Use UUID v4 When:
- Generating API Keys, Secret Webhook Tokens, or cryptographic Password Reset URLs. Because v7 exposes the literal exact creation microsecond physically natively in the front of the string, it mathematically structurally technically leaks minor peripheral metadata natively. For completely blind secure hashing, v4 retains mathematically superior intrinsic raw cryptographic unpredictability natively.
Generate Them Instantly
Need a bulk payload of v4 identifiers directly for a complex mock database seeder? Try our free robust client-side UUID Generator to dynamically generate up to 5,000 uniquely randomized completely secure architectural identifiers immediately directly within your local secure browser natively.